[译]海量 PDF 文件导入:Gemini 2.0 为何带来变革
2025 年 1 月 15 日
对于任何 RAG 系统来说,将 PDF 文件分块——转换为清晰、机器可读的文本块——都是个大难题。市面上既有开源方案,也有商业方案,但没有哪一种能真正做到准确、可扩展和经济高效的理想结合。
- 现有的端到端模型难以处理真实文档中常见的复杂排版。其他开源方案通常需要协调多个专门的机器学习模型,用于版面检测、表格解析和 Markdown 转换。例如,英伟达的 nv-ingest 就需要启动一个 Kubernetes 集群,包含八个服务和两块 A/H100 GPU。这不仅部署繁琐,而且性能仍然欠佳。
- 许多商业方案虽然价格昂贵,但在处理复杂排版和保持稳定准确率方面仍然吃力。此外,当数据量巨大时,费用会变得天文数字。对于我们的需求——解析数亿页文档——供应商的报价简直无法承受。
大型基础模型似乎很适合这项任务。然而,它们尚未证明比商业方案更具成本效益,而且其细微的不一致性也给实际应用带来了重大挑战。例如,GPT-4o 经常会在表格中生成虚假的单元格伪影,使其难以在生产环境中使用。
Gemini Flash 2.0 的出现改变了这一切。
虽然在我看来,谷歌的开发者体验仍然落后于 OpenAI,但其成本效益却令人无法忽视。与 1.5 Flash 不同,后者存在细微的不一致性,难以在生产环境中可靠使用,但我们的内部测试表明,Gemini Flash 2.0 在保持极低成本的同时,实现了近乎完美的 OCR 准确率。
| 供应商 | 模型 | 每美元可处理 PDF 页数 |
|---|---|---|
| Gemini | 2.0 Flash | 🏆 ≈ 6,000 |
| Gemini | 2.0 Flash Lite | ≈ 12,000 (尚未测试) |
| Gemini | 1.5 Flash | ≈ 10,000 |
| AWS Textract | 商业方案 | ≈ 1000 |
| Gemini | 1.5 Pro | ≈ 700 |
| OpenAI | 4o-mini | ≈ 450 |
| LlamaParse | 商业方案 | ≈ 300 |
| OpenAI | 4o | ≈ 200 |
| Anthropic | claude-3-5-sonnet | ≈ 100 |
| Reducto | 商业方案 | ≈ 100 |
| Chunkr | 商业方案 | ≈ 100 |
所有 LLM 供应商均采用批量定价 [2]。
成本降低是否以牺牲准确率为代价?
在文档解析的所有步骤中,表格识别和提取是最具挑战性的环节。复杂的排版、不规范的格式和参差不齐的数据质量都使得可靠提取变得困难。
因此,表格解析是评估性能的绝佳切入点。我们使用了 Reducto 的 rd-tablebench 的一个子集,它针对现实世界中的挑战(如扫描质量差、多语言和复杂的表格结构)对模型进行测试——远超学术基准中常见的整洁示例。
结果如下(准确率使用 Needleman-Wunsch 算法 衡量)。
| 供应商 | 模型 | 准确率 | 备注 |
|---|---|---|---|
| Reducto | 0.90 ± 0.10 | ||
| Gemini | 2.0 Flash | 0.84 ± 0.16 | 接近完美 |
| Anthropic | Sonnet | 0.84 ± 0.16 | |
| AWS Textract | 0.81 ± 0.16 | ||
| Gemini | 1.5 Pro | 0.80 ± 0.16 | |
| Gemini | 1.5 Flash | 0.77 ± 0.17 | |
| OpenAI | 4o | 0.76 ± 0.18 | 有轻微的数字幻觉 |
| OpenAI | 4o-mini | 0.67 ± 0.19 | 较差 |
| Gcloud | 0.65 ± 0.23 | ||
| Chunkr | 0.62 ± 0.21 |
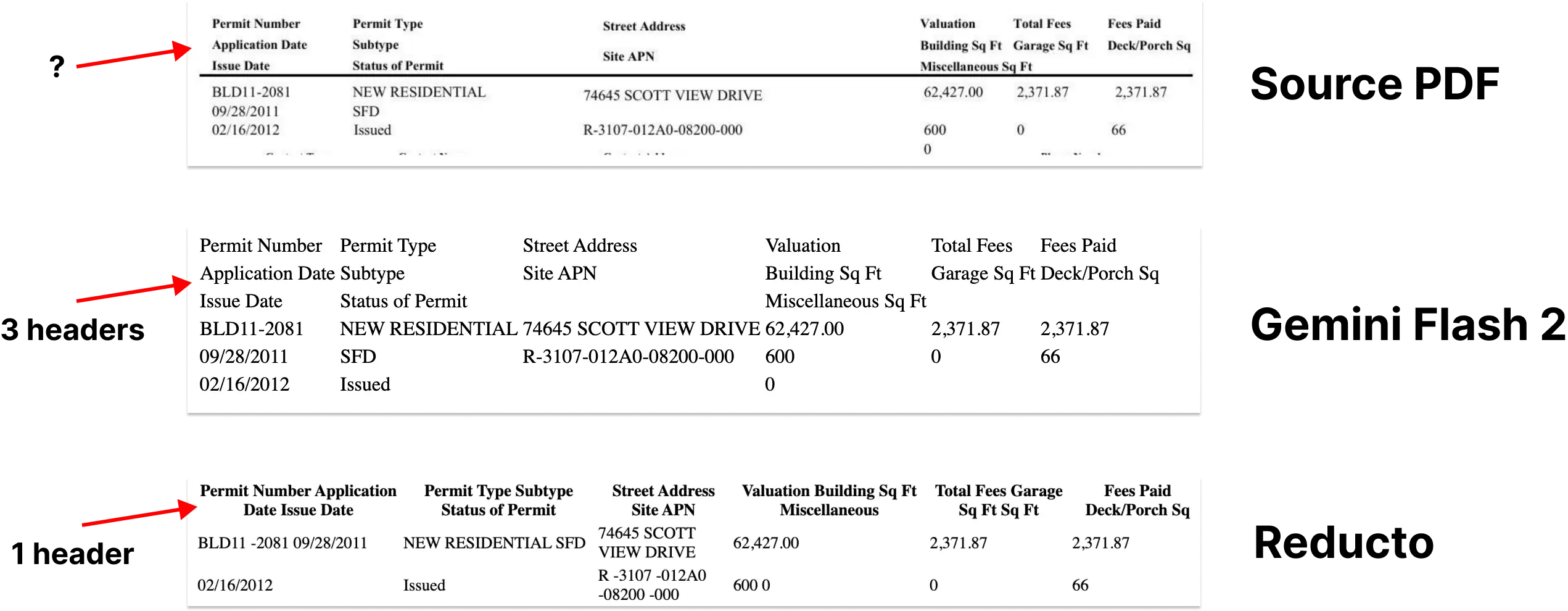
Reducto 自己的模型目前在这个基准测试中优于 Gemini Flash 2.0(0.90 对 0.84)。然而,当我们查看那些表现较差的例子时,发现大多数差异都是细微的结构变化,这些变化不会对 LLM 理解表格内容产生实质性影响。
至关重要的是,我们很少看到具体的数值被误读的情况。这表明 Gemini 的大多数“错误”是表面的格式选择,而不是实质性的不准确。我们在下面附上了这些失败案例的示例 [1]。
除了表格解析,Gemini 在 PDF 到 Markdown 转换的所有其他方面都始终如一地提供近乎完美的准确率。综合来看,你会得到一个极其简单、可扩展且廉价的索引管道。
如果加上分块呢?
Markdown 提取只是第一步。为了使文档能够有效地用于 RAG 管道,必须将其拆分成更小、语义相关的块。
最近的研究表明,在这个任务中使用大型语言模型 (LLM) 在检索准确率方面可以胜过其他策略。这在直觉上是合理的——LLM 擅长理解上下文并识别文本中的自然边界,这使得它们非常适合生成语义相关的块。
问题是?成本。到目前为止,基于 LLM 的分块成本一直高得令人望而却步。然而,Gemini Flash 2.0 的出现再次改变了局面——它的定价使得大规模使用它来分块文档成为可能。
我们可以用 Gemini Flash 2.0 花费 5,000 美元解析我们超过 1 亿页的语料库,这甚至低于一些向量数据库主机 的月账单。
你甚至可以想象将分块与 Markdown 提取结合起来,根据我们非常有限的测试,结果似乎有效,且对提取质量没有影响。
CHUNKING_PROMPT = """\
OCR the following page into Markdown. Tables should be formatted as HTML.
Do not sorround your output with triple backticks.
Chunk the document into sections of roughly 250 - 1000 words. Our goal is
to identify parts of the page with same semantic theme. These chunks will
be embedded and used in a RAG pipeline.
Surround the chunks with <chunk> </chunk> html tags.
"""但我们失去了边界框?
虽然 Markdown 提取和分块解决了文档解析中的许多问题,但它们也引入了一个关键的局限性:边界框信息的丢失。这意味着用户无法再看到特定信息在原始文档中的位置。相反,引用最终指向通用的页码或孤立的摘录。
这造成了信任鸿沟。边界框对于将提取的信息链接回其在源 PDF 中的确切位置至关重要,从而让用户确信数据并非凭空捏造。
这可能是我对绝大多数分块库最大的不满。

这是我们的应用程序,示例引用显示在源文档的上下文中。
但这里有一个很有希望的想法——LLM 已经展现出卓越的空间理解能力,(看看 Simon Willis 举的 Gemini 为密集的鸟群生成精确边界框的例子 )。你可能会认为可以利用它来精确地将文本映射到文档中的位置。
这曾是我们的一大希望。不幸的是,Gemini 在这方面似乎真的力不从心,无论我们如何提示,它都会生成非常不准确的边界框,这表明文档布局理解在其训练数据中代表性不足。即便如此,这看起来真的只是一个暂时的问题。
如果谷歌在训练期间加入更多特定于文档的数据——或者通过微调专注于文档布局——我们很可能可以相当容易地弥合这一差距。潜力是毋庸置疑的。
GET_NODE_BOUNDING_BOXES_PROMPT = """\
Please provide me strict bounding boxes that encompasses the following text in the attached image? I'm trying to draw a rectangle around the text.
- Use the top-left coordinate system
- Values should be percentages of the image width and height (0 to 1)
{nodes}
"""
真实情况——你可以看到 3 个不同的边界框包围着表格的不同部分。
*这只是一个示例提示,我们在这里尝试了很多不同的方法,但似乎都没有奏效(截至 2025 年 1 月)。
为何至关重要
通过整合这些方案,我们构建了一个优雅且经济高效的大规模索引管道。我们最终将开源我们在这一领域的工作,尽管我相信许多其他人也会实现类似的库。
重要的是,一旦我们解决了解析、分块和边界框检测这三个挑战,我们就有效地“解决”了将文档导入 LLM 的问题(但有一些注意事项)。这一进展使我们无比接近这样一个未来:文档解析不仅高效,而且对于任何用例都几乎毫不费力。
订阅以获取后续更新?
脚注:
[1] 查看失败案例。我们比较了 Gemini、Reducto 和源 PDF 的 HTML 输出。
[2] 我已经收到关于这个问题的疑问,所以这里是我如何分解 Gemini Flash 2.0 的成本的。输入图像成本 - 每张图像 0.00009675 美元。输出成本 - 每 400 个 token 0.0000525 美元。这相当于每美元 6,379 页 。密集页面可能成本更高,但这提供了一个可靠的估计。有关更多详细信息,请查看 Vertex 的批量定价页面。